
As stated in the previous parts of this blog series, malicious actors on the internet are currently taking advantage of the financial and wellness insecurity that came with COVID-19. We are seeing more ransomware, malware, and data exfiltration attacks during COVID than ever before and unprotected victims of ransomware have 2 options.
- Option 1: Pay the ransom and hope the malicious actor unlocks your resources.
- or Option 2: Throw all affected equipment away, and rebuild your environment from the ground up.
With downtime costing $500,000 per hour on average, disaster recovery is a no-brainer investment for protecting your workloads and data from Ransomware or other service interruptions.
HOW CAN DISASTER RECOVERY HELP YOU?
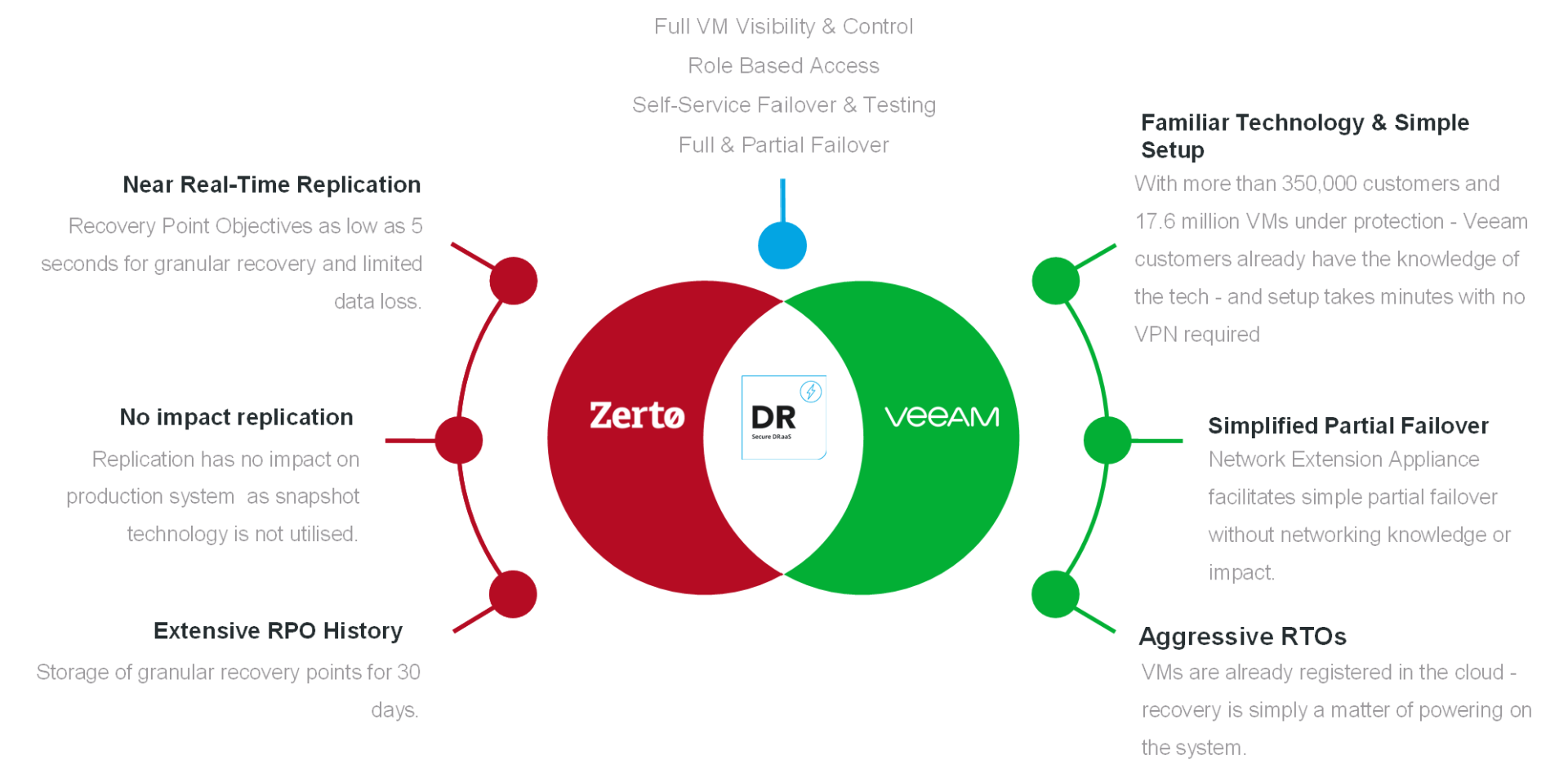
Disaster or site recovery can be used to keep your workloads running after a disaster event causes your infrastructure to be unavailable. DR boasts significantly faster RPOs and RTOs than backup restorations. RPOs are recovery point objectives, your most recent restore point, and RTOs are recovery time objectives, which is the amount of time needed to be up and running after service disruption. Most disaster recovery technologies work by maintaining an offline replica of your protected workloads at a separate site.

With private cloud disaster recovery, that replica, or fail-over site, is a data center separate from your main site. Private cloud disaster recovery has a higher CapEx, but much lower OpEx, than public cloud disaster recovery, as you will have to purchase the equipment capable of running your protected workloads. Private cloud disaster recovery is also vulnerable to equipment failure, power loss, natural disaster, and any other threats that come with maintaining your own data centers.
Public cloud disaster recovery maintains the fail-over sites in a cloud provider's workload, such as
Azure,
AWS, or iLand. Public cloud disaster recovery only has the cost of licensing in CapEx, but the OpEx can get costly depending on the size and utilization of your protected resources. However, public cloud disaster recovery can be configured to be geo-redundant, meaning your workloads can keep running even if your entire data center goes down for good. Since it's running off your network, public cloud disaster recovery is the best defense against ransomware. The most secure and available business continuity plans typically configure disaster recovery for multi-site, where their workloads are replicated to multiple private and public cloud fail-over sites.
CONTACT AKINS IT
If you'd like to begin building a business continuity plan, or review one that hasn't been updated recently, reach out to Akins IT to learn more about our Managed Disaster Recovery as a Service solution bundles.



