
FortiClient EMS Platform for Endpoint Security Deployment & Management
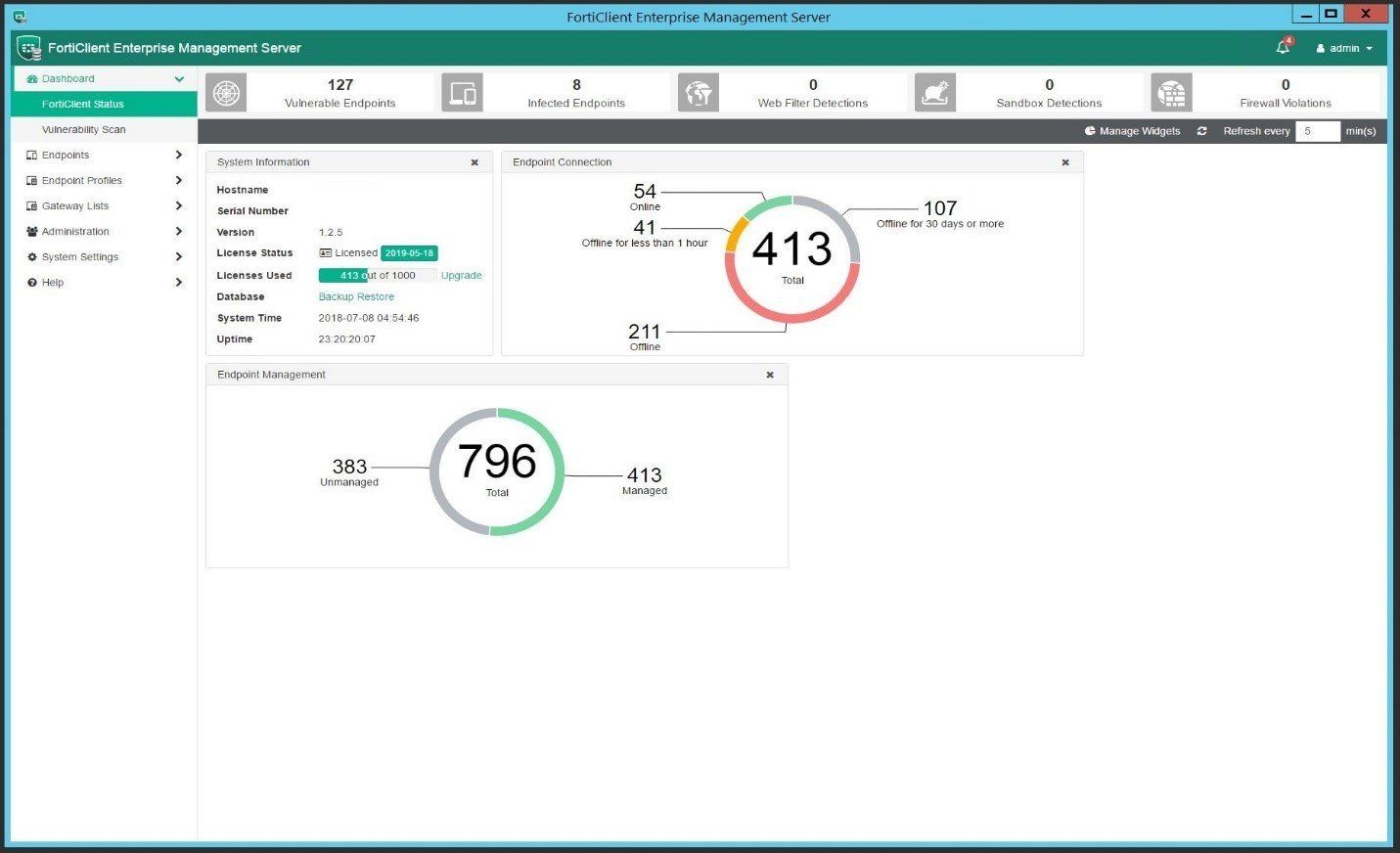
I last wrote about the powerful yet free AV and vulnerability endpoint protection solution offering by Fortinet called FortiClient and how it can be integrated with other Fortinet security fabric solutions to unlock enhanced features. One of those is achieved by leveraging the FortiClient EMS platform.
Device Management and Profiles
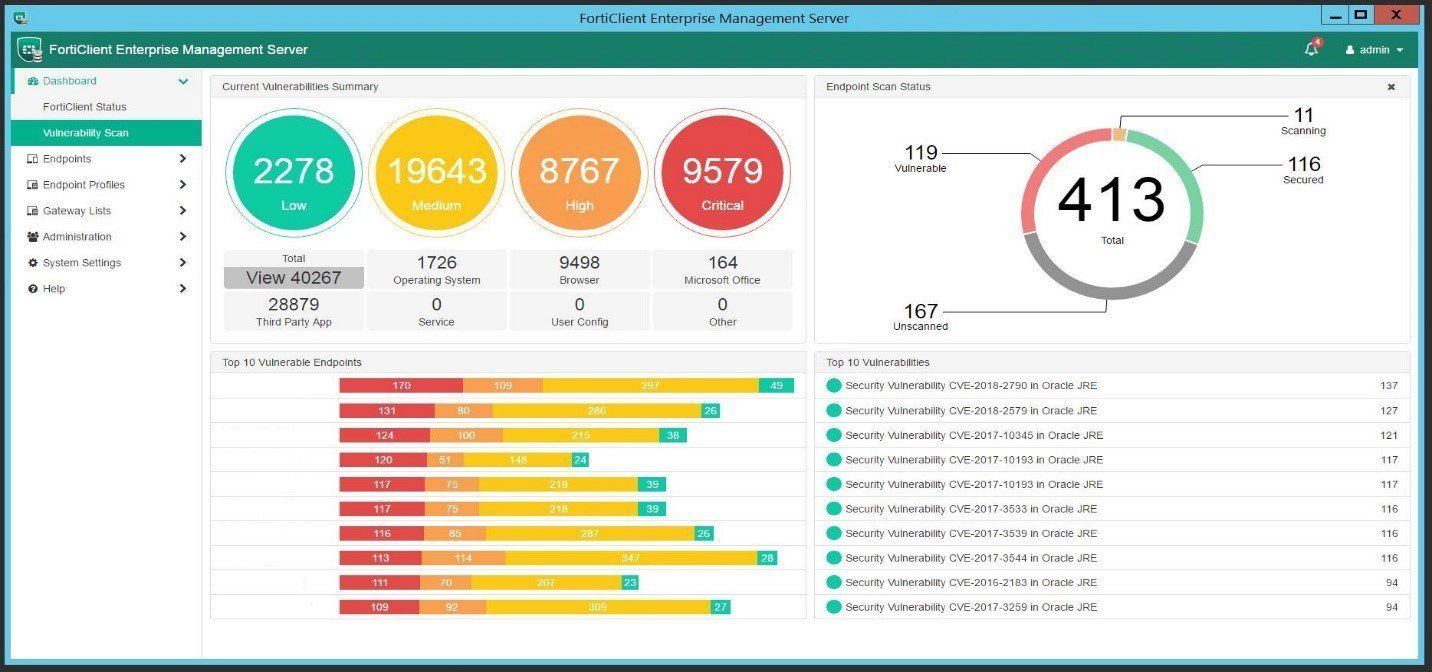
As mentioned before, FortiClient EMS can be deployed on a Windows Server 2012 R2 or higher system and provides an easy to use console for the management of FortiClient endpoints. The vulnerability dashboard also provides a high-level view of the overall endpoint security health at a glance.
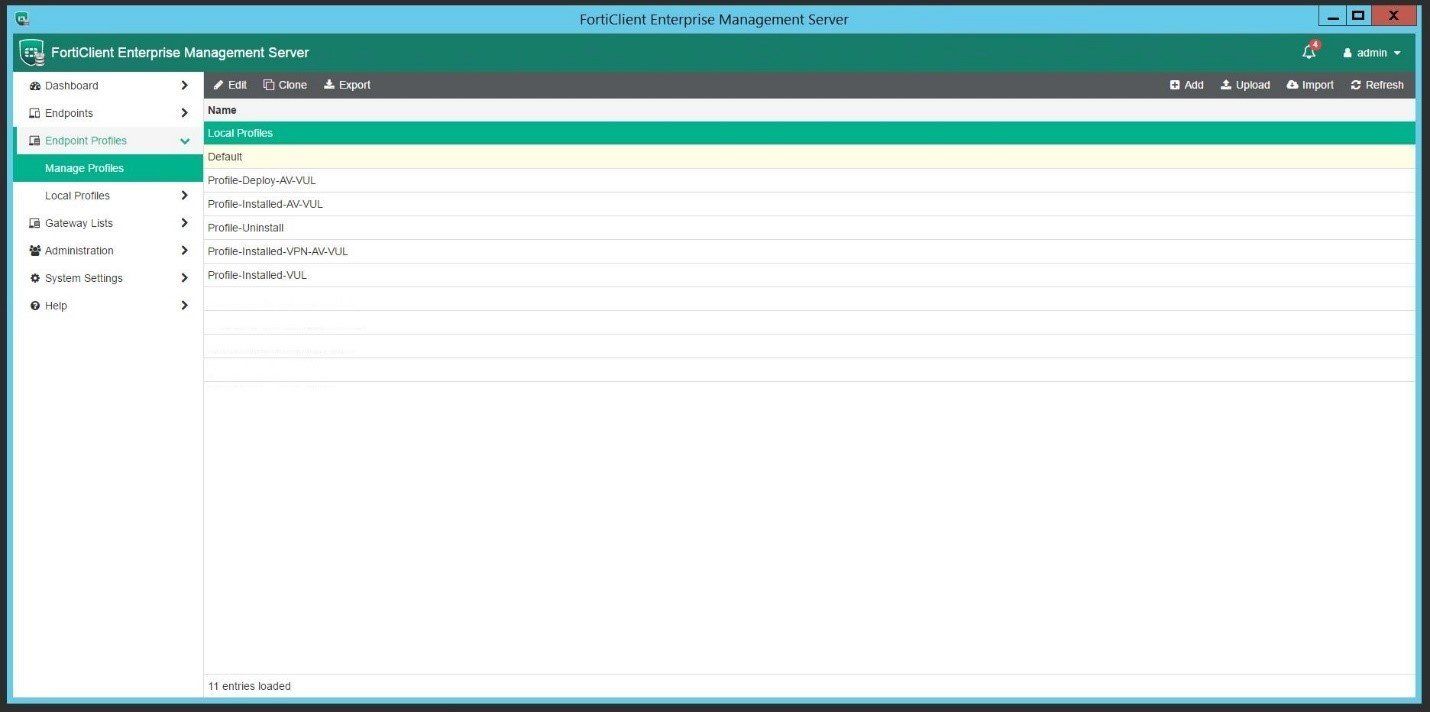
Endpoints can also be moved into separate containers / groups allowing for customized profiles to be created and deployed. These profiles can range from custom AV and Vulnerability scanning options to web filtering and application firewall enforcement based on user type (ie. Staff, Student, Admin).
Leveraging profiles helps to not only organize the deployment and management of different device groups, but also assist in simple tasks such as disabling AV under special circumstances. The process to disable AV on some endpoint solutions can be pretty convoluted and can sometimes even require client uninstall to do so – in FortiClient EMS, it’s as simple as moving the device(s) into a container with a profile that has AV disabled. To re-enable, just move it back to the original container.
Web and Application Firewall
The web filtering and application firewall modules can be implemented to add an additional layer of security and compliance to endpoints. The enforcement of content as well as management of profiles and settings can persist even while the device is off-net. Off-net management is achieved by making the FortiClient EMS server accessible from the outside - endpoints can be configured to send its telemetry data to an outside gateway which then also allows profile changes to be synced.
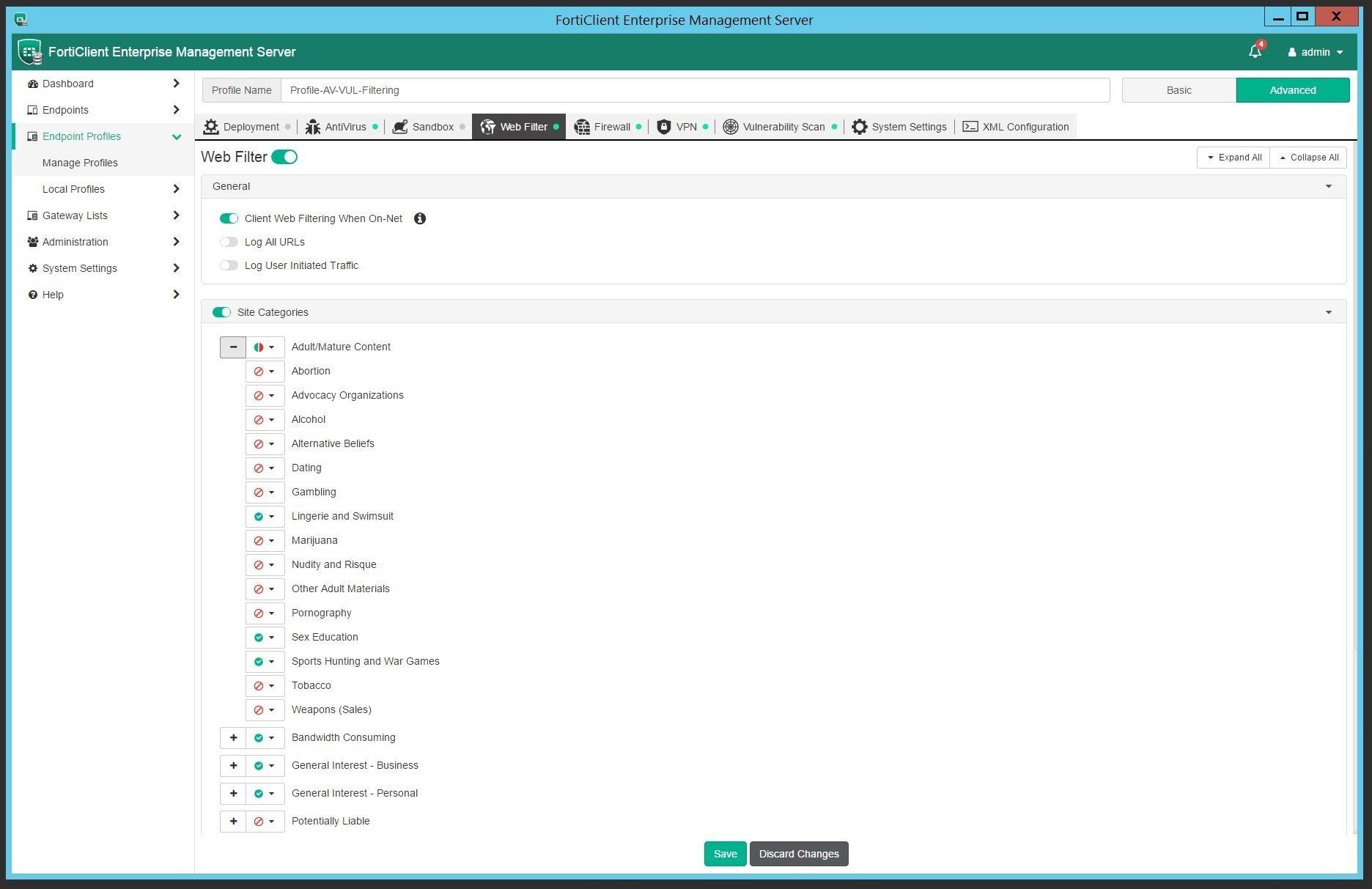
Choose from block, allow or monitor for each web and application category.
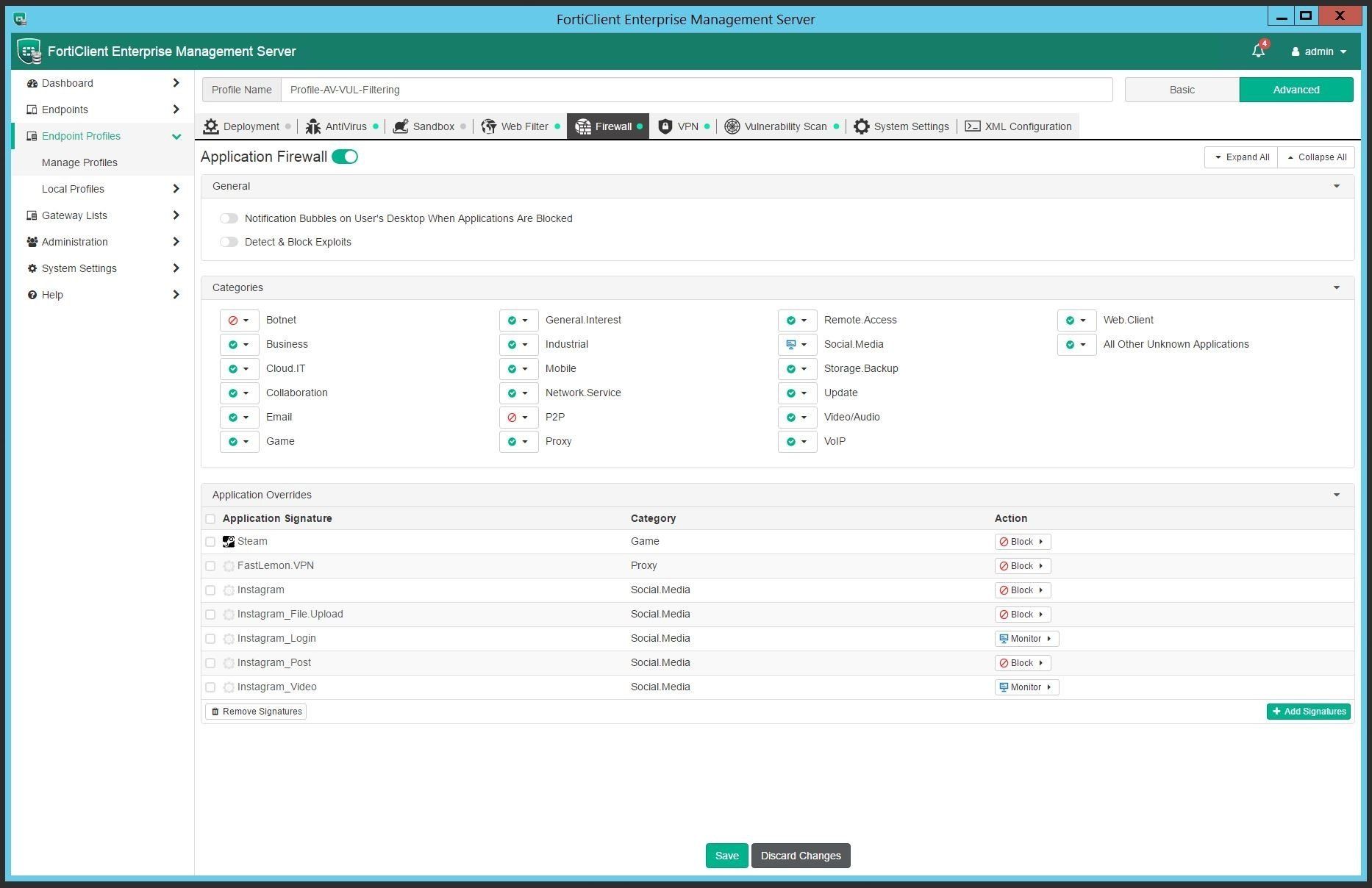
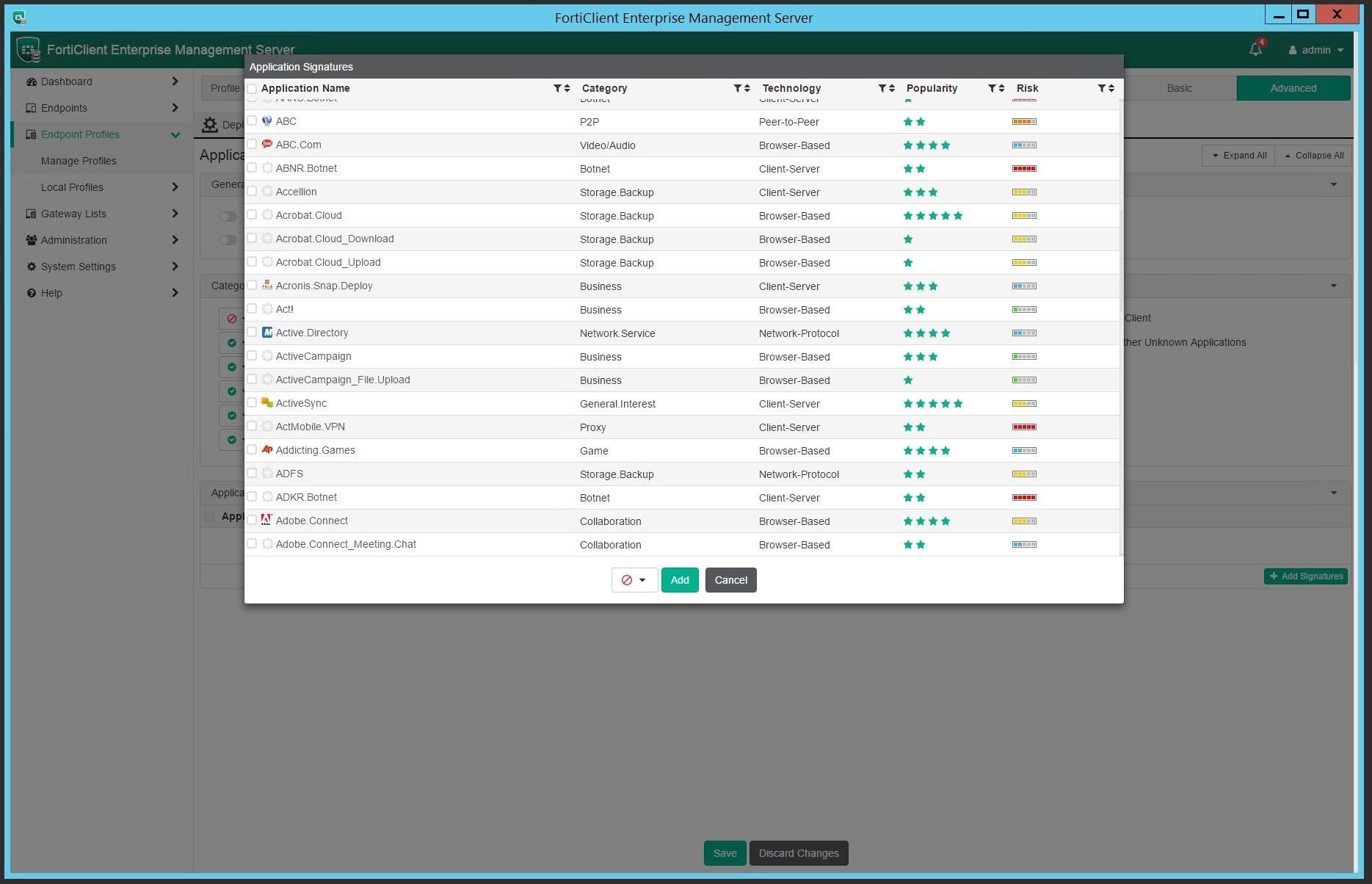
Get more granular by selecting application signatures and applying block, allow or monitor status as needed.
Logging and Reporting
FortiClient EMS can also send traffic and event logs to a FortiAnalyzer, allowing for additional visibility into endpoint security events. Reporting options are also available from the FortiAnalyzer.



