
A common question I get as a solution architect is “Why?” Why that firewall? Why that server? Why do it that way?" In this write up I’d like to dive a little bit into why I enjoy working with Nimble Storage and some of the benefits we see our clients taking advantage of.
Simple
Just about anything you could want to do with your storage appliance is easy with Nimble. With some storage appliances, performing basic setup or making configuration changes is very complicated and not user friendly. Hence, why some companies must bring in a storage expert. I am not trying to talk myself out of work here, but with some basic understanding of storage, most IT admins can setup and manage a Nimble infrastructure with ease.
If you need more performance for a workload, simply apply a pre-built or custom performance policy to the volume where the workload resides. If you want the best performance for some workloads but don’t have the budget for all flash, pin the specific workload to cache. It is all very simple and seamless. If business goals demand disaster recovery readiness, purchase a second array for the DR site, enable replication. Done.
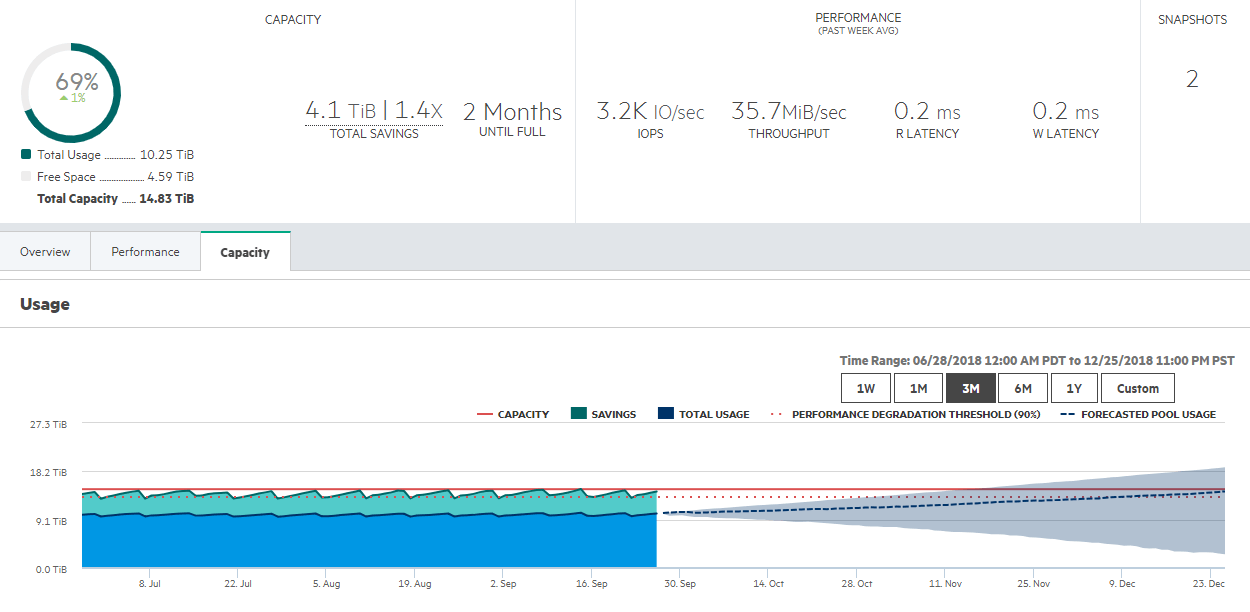
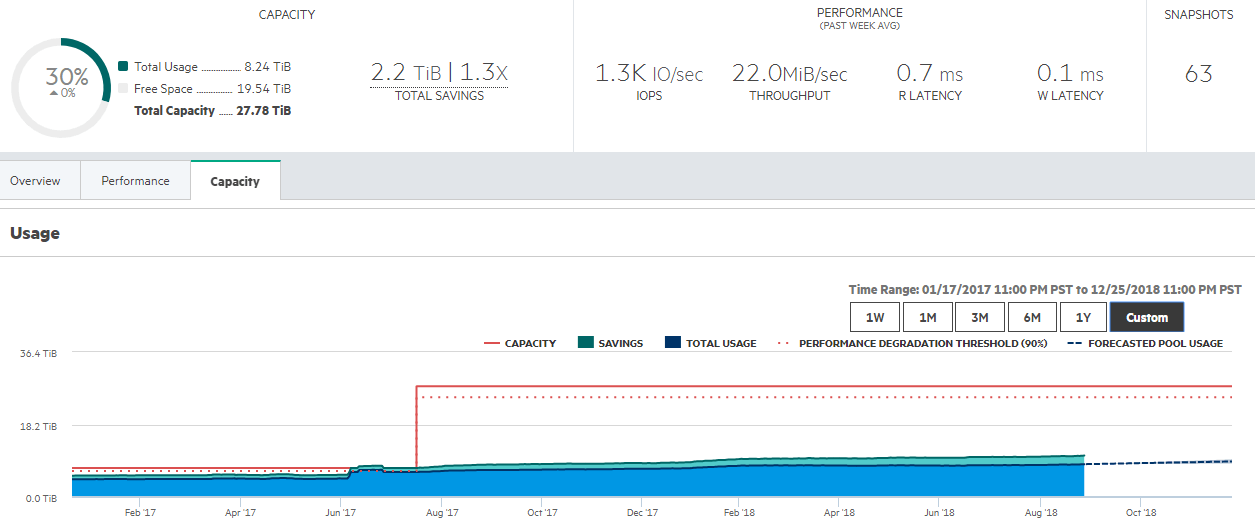
I have seen the situation many times where a company’s storage has run out or is about to run out with relatively short notice. To remedy, they must spend $50,000 or more on storage but it’s not in the budget this year. Unfortunately, this is not uncommon. Nimble has a neat feature where the array will give you predictive analytics based on past data growth as to when your array will run out of space and make recommendation to add another array or shelf.
Flexibility
Say you came across the situation where the business decided to expand, larger projects are started, or you’ve simply had the same infrastructure for 3-5 years. Its time to increase your storage capacity. In some situations, this is a massive undertaking and a lot of planning, preparation, and ground work needs to be done. With Nimble, the purchase of an expansion shelf fixes your problem as fast as you can plug it in. I have done this for customers many times and they are always surprised at how easy it is. All you must do is point the array to recognize the shelf and expand the storage pool. Incredibly quick to do. Of course, make sure you have the rack space, I’ve seen that one go bad.
In other situations, you might have enough storage, but you need more performance, which is not a problem. You can perform a controller upgrade at any time and even during production. If required, you can even add an all flash shelf to a hybrid array and use the shelf for the caching of your performance intensive workloads.
Support
Last but certainly not least is Nimble support… Wow! As a solution architect, I deal with a lot of different companies and their support staff. I can honestly say Nimble support is some of the best out there. When you call in, there is no “Let me make a case for you and someone will call you back next month.” There is no, “Sir, can you please unplug it and plug it back in?” You speak to an experienced engineer immediately who knows what they are talking about. Not only experienced with Nimble, but the surrounding infrastructure as well- i.e. VMware, Hyper-V, Server OS, Switching, etc. Often when I am explaining Nimble support to customers I have them call their support line and quiz the engineer. Never have I had a client bothered by the support experience. I dare you, too! Give them a call and quiz them.
In summary, Nimble Storage is a great fit for a variety of scenarios. Hopefully this write-up answers the “Why?” question for a lot of you!



