
What do you think may be the weakest point in your network? It’s probably not the firewall protecting the network from hackers, but may be the end user sitting on an end-point visiting a phishing site that is about to harvest their credentials. Carelessness often leads to environment and network breaches. An attacker’s primary tool isn’t Mimikatz, but the daily driver of productivity in every business: email.
When determining a security gateway that’s right for your company, it’s important to determine the number of users, compliance the company must meet, and the importance of security. My local coffee shop isn’t going to need the same level of security as my bank. Again, it’s about assessing the needs of the company to find the right solution.
Traditional security email gateways are easier to use and have a lower cost associated. Implementation can be as easy as flipping an MX record to point to the gateway. Console management usually provides basic reporting and policies can be spun up within a few hours. Policies include URL rewrites and attachment sandboxing. Microsoft’s O365 ATP features these security mechanisms in their offering, as an example.
Mimecast, a leader in email security, provides granular policies for enterprise. Attachment Protect isn’t only limited to sandboxing at the gateway. Its capabilities are enhanced to provide file conversion where necessary. For example, Office documents can be converted into a PDF, stripping any malicious metadata from the document. Mimecast excels in its ability to create in-depth policies for departmentalized companies.
Below are a few screenshots to illustrate the differences of the two gateways listed.
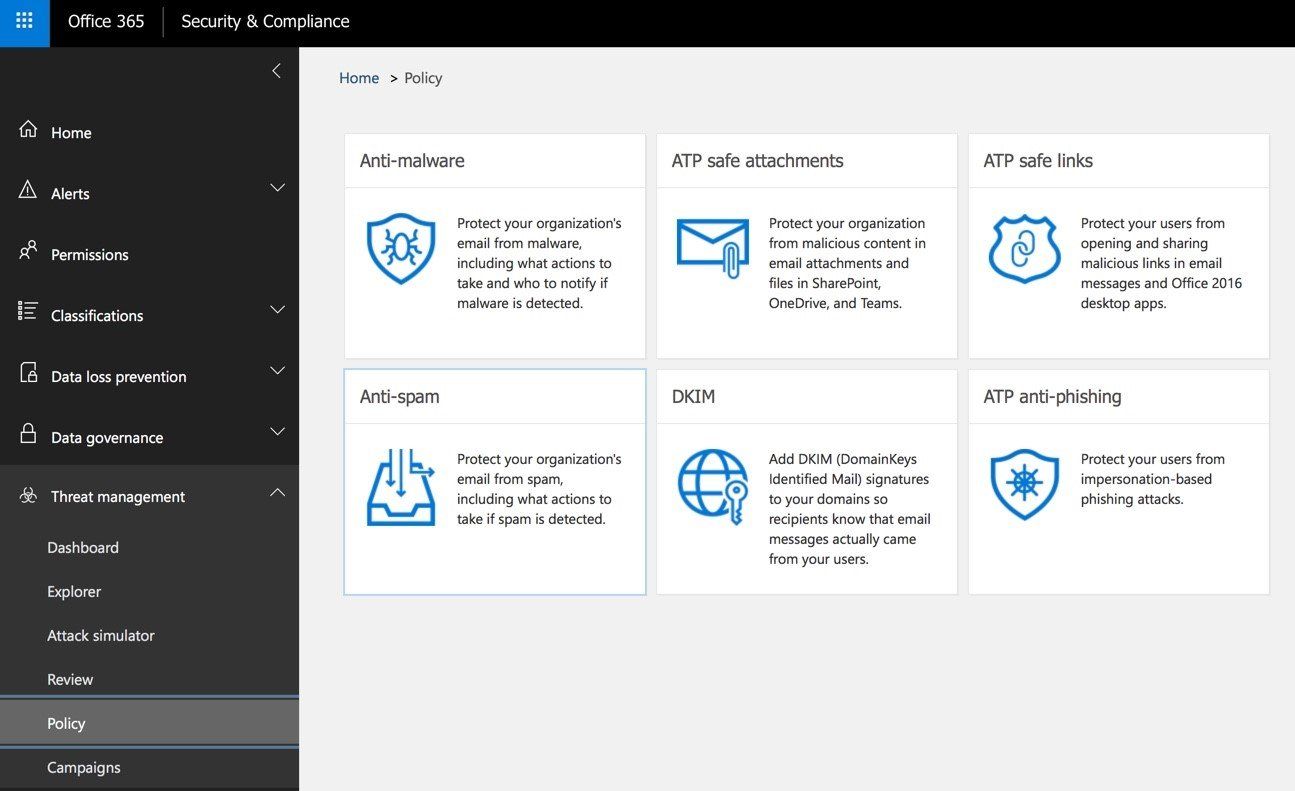
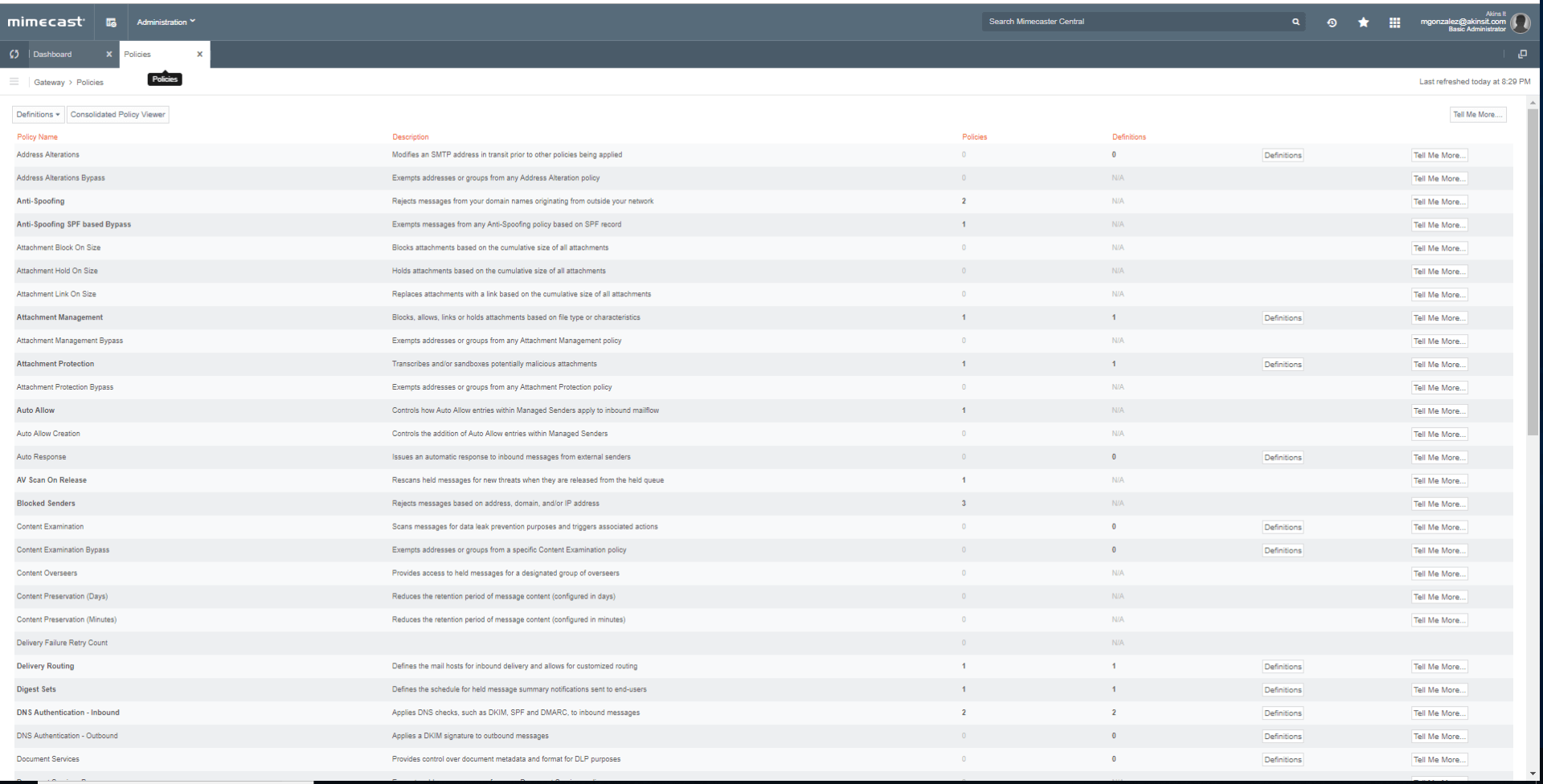
The company and IT department shouldn't place the responsibility of security on the end user; they're bound to accidentally click on a link for a malicious site at some point. It's the IT department's responsibility to ensure their network is secure and engage their company’s security posture with a focus on email security as these types of attacks become more frequent.



