
Unleashing Productivity: Maximizing Potential with Copilot for Microsoft 365 and Akins IT
Many organizations are grappling with the challenges posed by the transition to a hybrid work model, prompting a turn towards generative AI for optimizing workflows and collaboration. The economic potential of generative AI is significant, with McKinsey estimating a potential annual contribution of US$4.4 trillion to the global economy by 2030. To tap into this market share, companies are introducing AI solutions like Copilot for Microsoft 365, aiming to maximize value. This tool, embedded in Microsoft 365 apps, utilizes Microsoft Graph for organizational context, offering personalized suggestions and insights based on users' needs and work patterns.
As you explore the potential of Copilot for Microsoft 365 to boost productivity in your organization, it's vital to focus on key considerations. The effectiveness of AI-assisted features depends on the quality and relevance of your data. While anticipating enhanced creativity, productivity, and automation, prioritize data quality, privacy, and security to establish a strong data foundation.
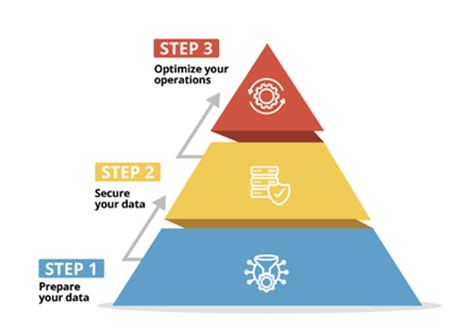
As part of our services, Akins IT emphasizes a three-step approach for organizations considering Copilot for Microsoft 365 adoption. We believe in the importance of preparing data, urging businesses to centralize content and migrate it to Microsoft 365. Next, our Copilot for Microsoft 365 Readiness Assessment and Remediation ensures your data is secure. And finally, we’ll ensure your organization is set up for success with the right controls so you can reap the benefits of Microsoft 365 long-term.
Addressing the shift in work dynamics, Akins IT is now offering tailored advisory and implementation services. This comprehensive approach encompasses the adoption of tools like Copilot for Microsoft 365, focusing on its integration into daily workflows and providing guidance on data preparation, security, and operational optimization.



