
Security breaches and hacking is on the news just about daily. Sony, the DNC, HBO…the list goes on and on. I speak with many other executives and often I hear "We don't have data we care about getting into the wrong hands, we just do manufacturing or education or ____". I remind them that they most likely have payroll, social security numbers of their employees, or other sensitive data that hackers would love to have.
To help combat and reduce the vulnerabilities in Office 365, Microsoft has come out with Secure Score. With this tool, you can quickly find out not only how secure your Office 365 organization really is but also a list of tasks you (or with the assistance of Akins IT of course) can do to increase your Secure Score.
HOW DO I GET TO SECURE SCORE?
Anyone who has admin permissions (global admin or a custom admin role) for an Office 365 Business Premium or Enterprise subscription can access the Secure Score at https://securescore.office.com. Users who aren’t assigned an admin role won't be able to access Secure Score . However, admins can use the tool to share their results with other people in their organization.
HOW DOES IT WORK?
Secure Score figures out what Office 365 services you’re using (like OneDrive, SharePoint, and Exchange) then looks at your settings and activities and compares them to a baseline established by Microsoft. You’ll get a score based on how aligned you are with best security practices.

If you want to improve your score, review the action queue to see what you can do to help increase security and reduce risks.

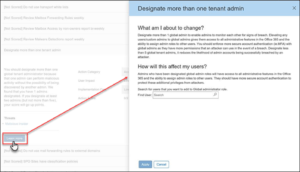
Expand an action to learn about what threats it’ll help protect you from and how you’ll get the job done.
To see the impact of your actions on your organization’s security, go to the Score Analyzer page and review your history.
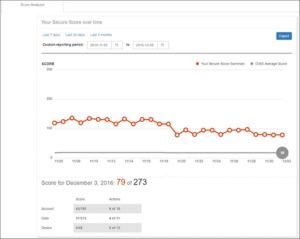
Click any data point to see a breakdown of your score for that day. You can scroll down to see which controls were enabled and how many points you earned that day for each control.




