
June 26, 2020/ /by Akins IT
Click here for part 3 of the blog series on data loss during COVID-19.
In part 3, we covered how site recovery is valuable to your business continuity plan, as well as the potential costs of not protecting your workloads. We also went over some the common measurables used to gauge the effectiveness of a DR solution, and a high level overview on the key differences between
Public and Private cloud site recovery.
WHAT DO THE LEADING DR SOLUTIONS HAVE TO OFFER?

AZURE SITE RECOVERY
Azure Site Recovery is a disaster recovery solution that ensures business continuity by keeping your workloads online during outages, planned or not. Site recovery replicates workloads from a primary (source) site to a secondary (destination) site. ASR can work protect physical, virtual, and Azure workloads, and can replicate Azure VMs between Azure regions.
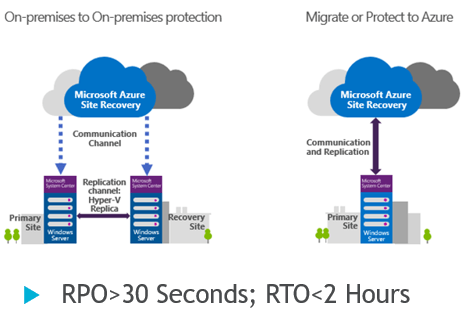
For being a relatively affordable option when considering a site recovery solution, Azure Site Recovery boasts some pretty competitive RPO's and RTO's. It also is easy to implement and integrate with existing Azure & Hyper-V environments and Azure Automation.
VEEAM REPLICATION
Veeam Replication is a feature of the Veeam Backup & Replication console. From that application, you can manage, configure, and receive reports on all of your backups and disaster protected workloads running on Veeam. This centralized backup and replication management, along with its award winning support, low costs, and integration with public cloud providers make Veeam the go to for most businesses.
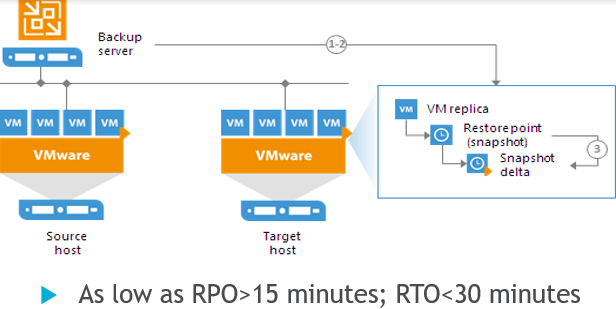
Veeam Replication works by requesting a snapshot from the hypervisor as often as every 15 minutes, then using those snapshots to track changes between the source and target workloads. Veeam is cloud agnostic, meaning you can replicate to any cloud provider.
ZERTO CONTINUOUS REPLICATION
Zerto is the industry leader in disaster recovery technologies. It works by continuously journaling changes between the source and makes those changes as they are written on the destination. Their unique technology gives you RPO's as short as 5 seconds, but it comes with a higher cost than ASR or Veeam.
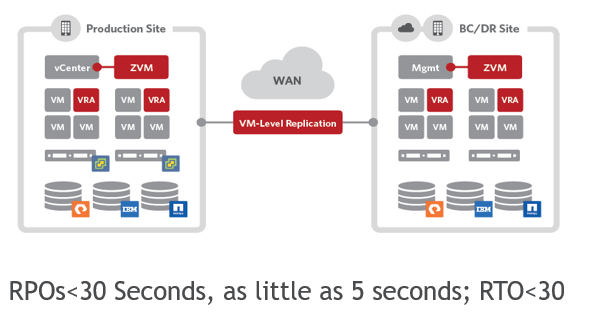
Of all the disaster recovery technologies, Zerto's ease of use can't be beat. To conduct a failover, simply click the workloads you want to activate on the destination site and click failover. It can also replicate to more than 2 sites at the same time, maintaining your workloads across multiple private clouds and different public cloud providers. This high availability and continuous replication make it a great fit for business with data sovereignty and availability requirements.
PLEASE CONTACT AKINS IT TO LEARN MORE ABOUT OUR MANAGED DISASTER RECOVERY AS A SERVICE BUNDLES AND DISCUSS YOUR BUSINESS CONTINUITY PLAN.



